
Website borrowed from NeRFies under a Creative Commons Attribution-ShareAlike 4.0 International
Framework
We propose Shape-for-Motion, a novel video editing framework that incorporates a 3D proxy to allow diverse and precise video object manipulation while ensuring temporal consistency across frames.
- We propose a video object reconstruction method, which produces meshes with correspondences across frames, and a dual propagation strategy. Together, these components enable a user-friendly editing process: users can perform edits directly on the canonical 3D mesh only once, with the edits are automatically propagated to subsequent frames.
- We propose a self-supervised mixed training strategy to train a decoupled video diffusion model that leverages geometry and texture information from the edited 3D proxy as control signals, achieving more consistent editing results.
Model Overview
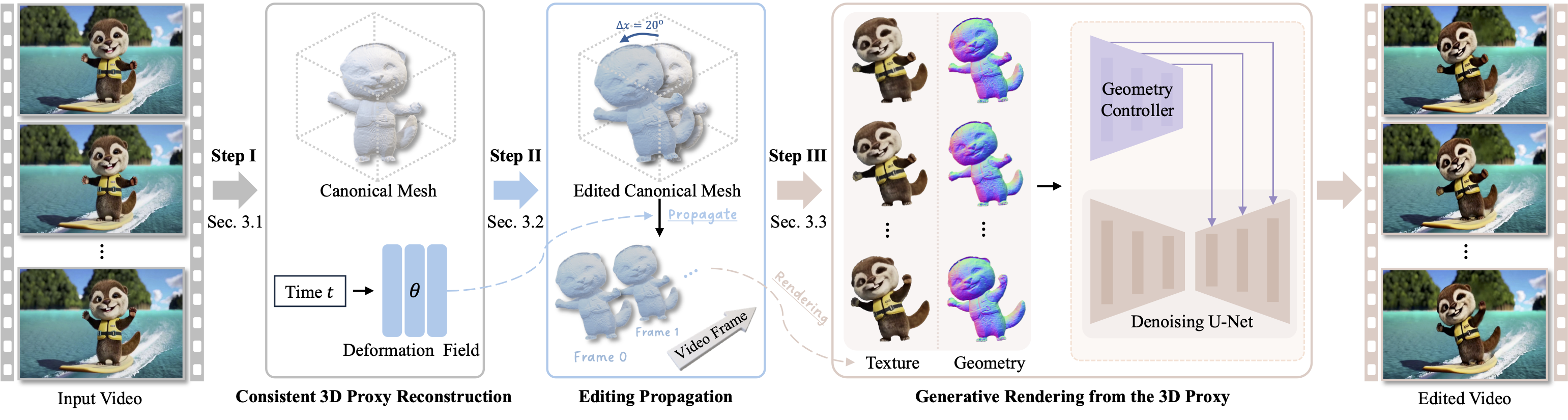
Overview of Shape-for-Motion. Our approach is an interactive video editing framework that utilizes an editable 3D proxy (e.g., mesh) to enable users to perform precise and consistent video editing. Given an input video, our approach first converts the target object into a 3D mesh with frame-by-frame correspondences. Users can then perform editing on this 3D proxy once only (i.e., on a single frame), and the edits will be automatically propagated to the 3D meshes of all other frames. The edited 3D meshes are then converted back to 2D geometry and texture maps, which are used as control signals in a decoupled video diffusion model to generate the final edited result.
Consistent 3D Proxy Reconstruction
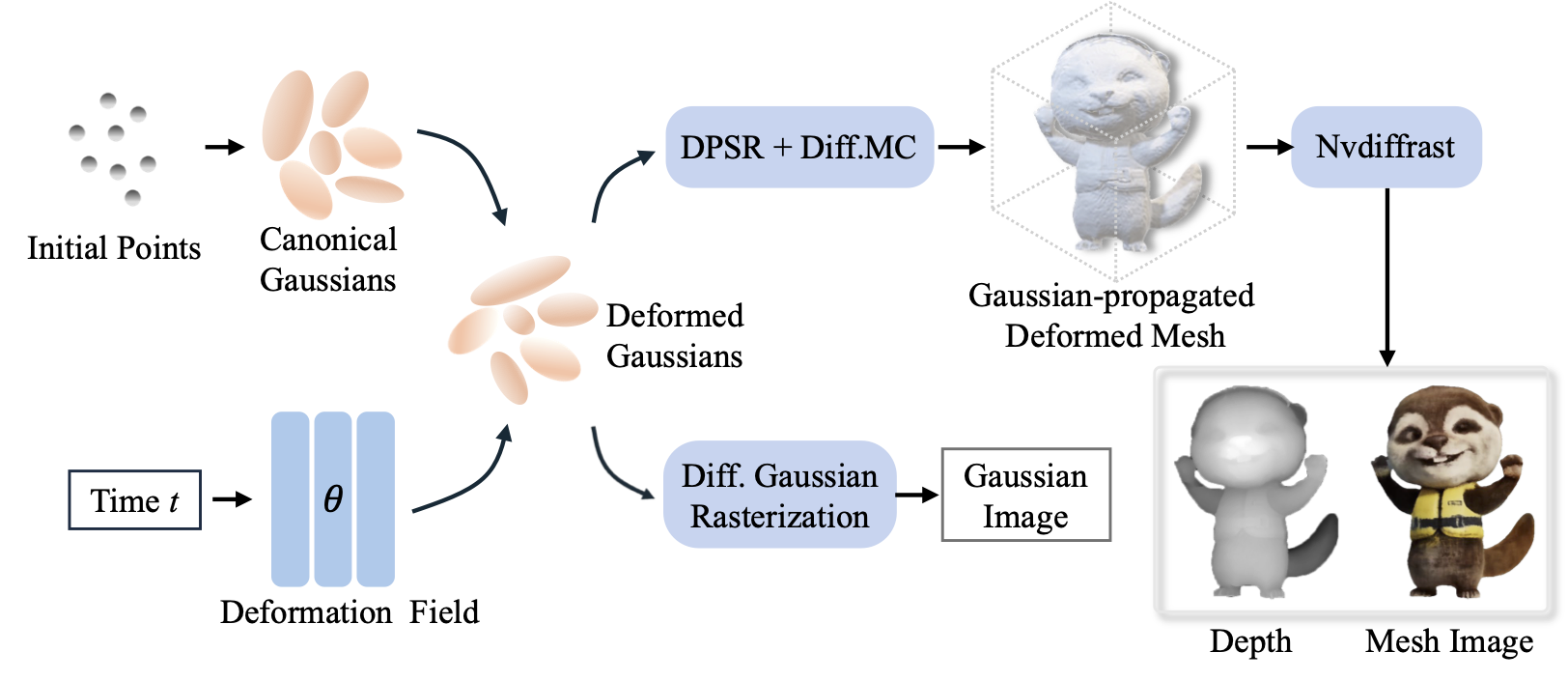
Pipeline of our consistent object reconstruction. We use deformable-3DGS to reconstruct the 3D mesh of the target object in a video by maintaining canonical Gaussians and a time-varying deformation field.
Editing 3D Proxy with Automatic Propagation

Workflow of our consistent editing propagation. Solid orange arrows denote texture propagation from the canonical mesh, and solid blue arrows indicate geometry propagation from canonical Gaussians.
Generative Rendering from the 3D Proxy
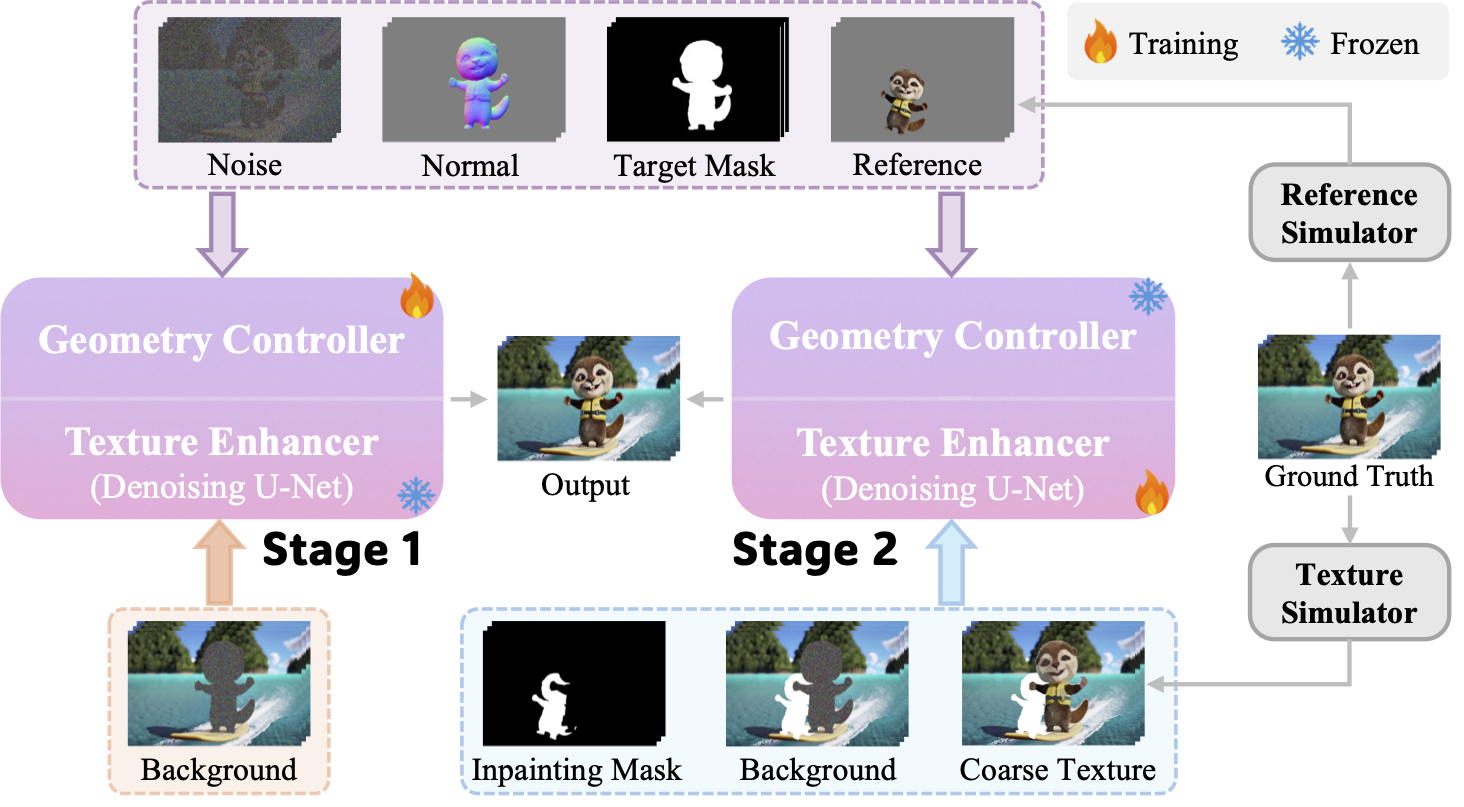
Training pipeline of the generative rendering from the 3D proxy. Using rendered geometry (i.e., normal map) and texture as separate control signals, we adopt a self-supervised mixed training strategy in which the geometry controller and the texture enhancer (i.e., denoising U-Net) are alternately trained in two stages.
The contents enclosed by the purple dashed box indicates inputs shared by both stages, while those in the orange and blue dashed boxes are specific to the first and second stages, respectively.
Applications
We demonstrate the effectiveness of our Shape-for-Motion framework in various applications.
Image-to-Video Animation
Appearance Editing
More Visual Results
Below we showcase additional qualitative results demonstrating the effectiveness of our Shape-for-Motion framework across different scenarios and editing operations, including both short and long video sequences.
BibTeX
@article{liu2025shape,
title={Shape-for-Motion: Precise and Consistent Video Editing with 3D Proxy},
author={Liu, Yuhao and Wang, Tengfei and Liu, Fang and Wang, Zhenwei and Lau, Rynson W.H.},
journal={arXiv preprint arXiv:2506.22432},
year={2025}
}